Provider Configuration
Multi-Provider Setup
Section titled “Multi-Provider Setup”Configure multiple providers to seamlessly switch between them. This example shows how to configure OpenAI, Anthropic, and Mistral providers.
- Go to http://localhost:8080
- Navigate to “Model Providers” in the sidebar
- Select provider and configure keys
# Add OpenAI providercurl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ]}'
# Add Anthropic providercurl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "anthropic", "keys": [ { "name": "anthropic-key-1", "value": "env.ANTHROPIC_API_KEY", "models": [], "weight": 1.0 } ]}'
# Add vLLM (self-hosted OpenAI-compatible server)curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "vllm-local", "keys": [ { "name": "vllm-key-1", "value": "dummy", "models": [], "weight": 1.0 } ], "network_config": { "base_url": "http://vllm-endpoint:8000", "default_request_timeout_in_seconds": 60 }, "custom_provider_config": { "base_provider_type": "openai", "allowed_requests": { "chat_completion": true, "chat_completion_stream": true } }}'{ "providers": { "openai": { "keys": [ { "name": "openai-key", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ] }, "anthropic": { "keys": [ { "name": "anthropic-key", "value": "env.ANTHROPIC_API_KEY", "models": [], "weight": 1.0 } ] }, "vllm-local": { "keys": [ { "name": "vllm-key", "value": "dummy", "models": [], "weight": 1.0 } ], "network_config": { "base_url": "http://vllm-endpoint:8000", "default_request_timeout_in_seconds": 60 }, "custom_provider_config": { "base_provider_type": "openai", "allowed_requests": { "chat_completion": true, "chat_completion_stream": true } } } }}Making Requests
Section titled “Making Requests”Once providers are configured, you can make requests to any specific provider. This example shows how to send a request directly to OpenAI’s GPT-4o Mini model. DeepIntShield handles the provider-specific API formatting automatically.
curl --location 'http://localhost:8080/v1/chat/completions' \--header 'Content-Type: application/json' \--data '{ "model": "openai/gpt-4o-mini", "messages": [ {"role": "user", "content": "Hello!"} ]}'Environment Variables
Section titled “Environment Variables”Set up your API keys for the providers you want to use. DeepIntShield supports both direct key values and environment variable references with the env. prefix:
export OPENAI_API_KEY="your-openai-api-key"export ANTHROPIC_API_KEY="your-anthropic-api-key"export MISTRAL_API_KEY="your-mistral-api-key"export CEREBRAS_API_KEY="your-cerebras-api-key"export GROQ_API_KEY="your-groq-api-key"export COHERE_API_KEY="your-cohere-api-key"Environment Variable Handling:
- Use
"value": "env.VARIABLE_NAME"to reference environment variables - Use
"value": "sk-proj-xxxxxxxxx"to pass keys directly - All sensitive data is automatically redacted in GET requests and UI responses for security
Advanced Configuration
Section titled “Advanced Configuration”Weighted Load Balancing
Section titled “Weighted Load Balancing”Distribute requests across multiple API keys or providers based on custom weights. This example shows how to split traffic 70/30 between two OpenAI keys, useful for managing rate limits or costs across different accounts.
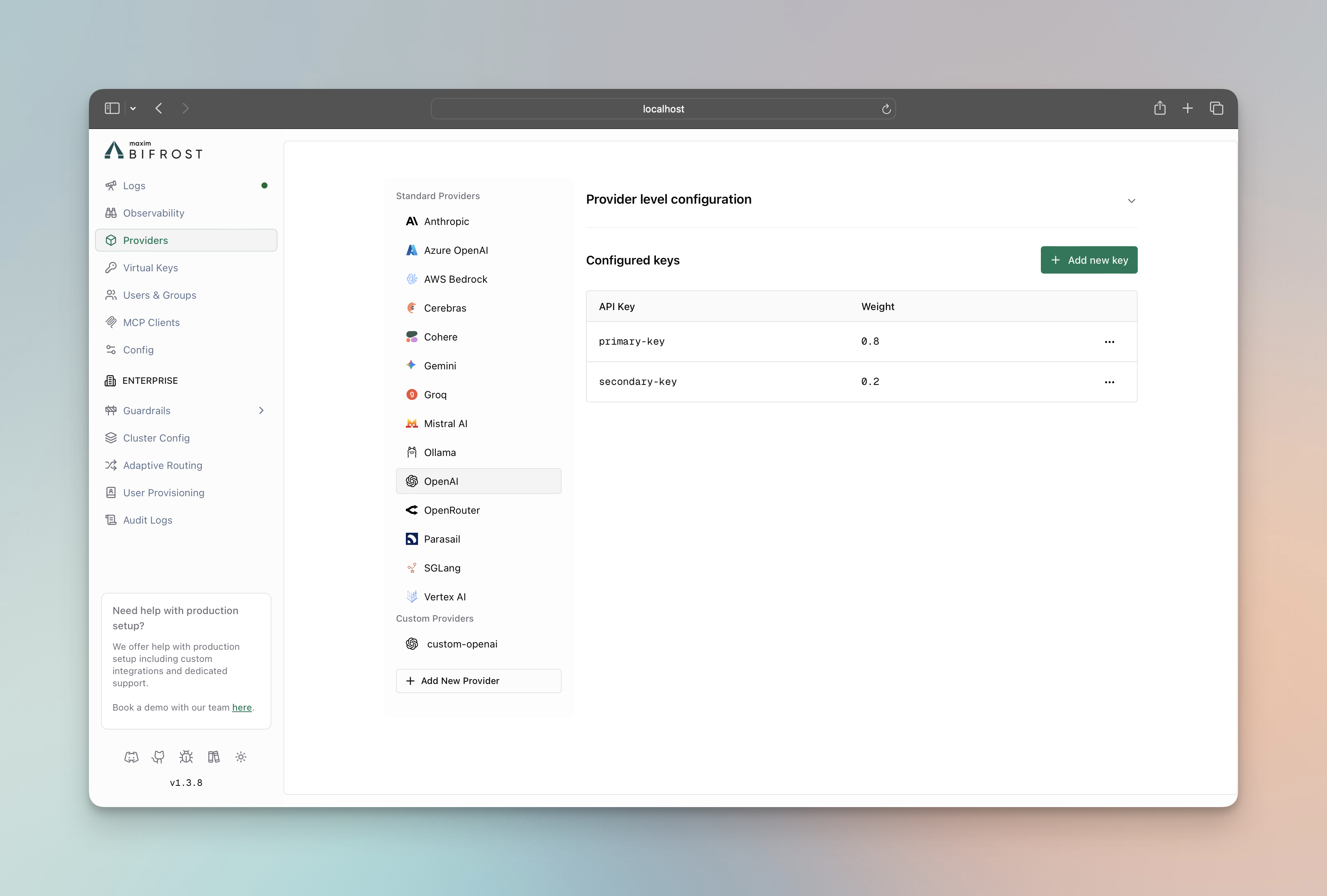
- Navigate to “Model Providers” → “Configurations” → “OpenAI”
- Click “Add Key” to add multiple keys
- Set weight values (0.7 and 0.3)
- Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY_1", "models": [], "weight": 0.7 }, { "name": "openai-key-2", "value": "env.OPENAI_API_KEY_2", "models": [], "weight": 0.3 } ]}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY_1", "models": [], "weight": 0.7 }, { "name": "openai-key-2", "value": "env.OPENAI_API_KEY_2", "models": [], "weight": 0.3 } ] } }}Model-Specific Keys
Section titled “Model-Specific Keys”Use different API keys for specific models, allowing you to manage access controls and billing separately. This example uses a premium key for advanced reasoning models (o1-preview, o1-mini) and a standard key for regular GPT models.
- Navigate to “Model Providers” → “Configurations” → “OpenAI”
- Add first key with models:
["gpt-4o", "gpt-4o-mini"] - Add premium key with models:
["o1-preview", "o1-mini"] - Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": ["gpt-4o", "gpt-4o-mini"], "weight": 1.0 }, { "name": "openai-key-2", "value": "env.OPENAI_API_KEY_PREMIUM", "models": ["o1-preview", "o1-mini"], "weight": 1.0 } ]}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": ["gpt-4o", "gpt-4o-mini"], "weight": 1.0 }, { "name": "openai-key-2", "value": "env.OPENAI_API_KEY_PREMIUM", "models": ["o1-preview", "o1-mini"], "weight": 1.0 } ] } }}Custom Base URL
Section titled “Custom Base URL”Override the default API endpoint for a provider. This is useful for connecting to self-hosted models, local development servers, or OpenAI-compatible APIs like vLLM, Ollama, or LiteLLM.
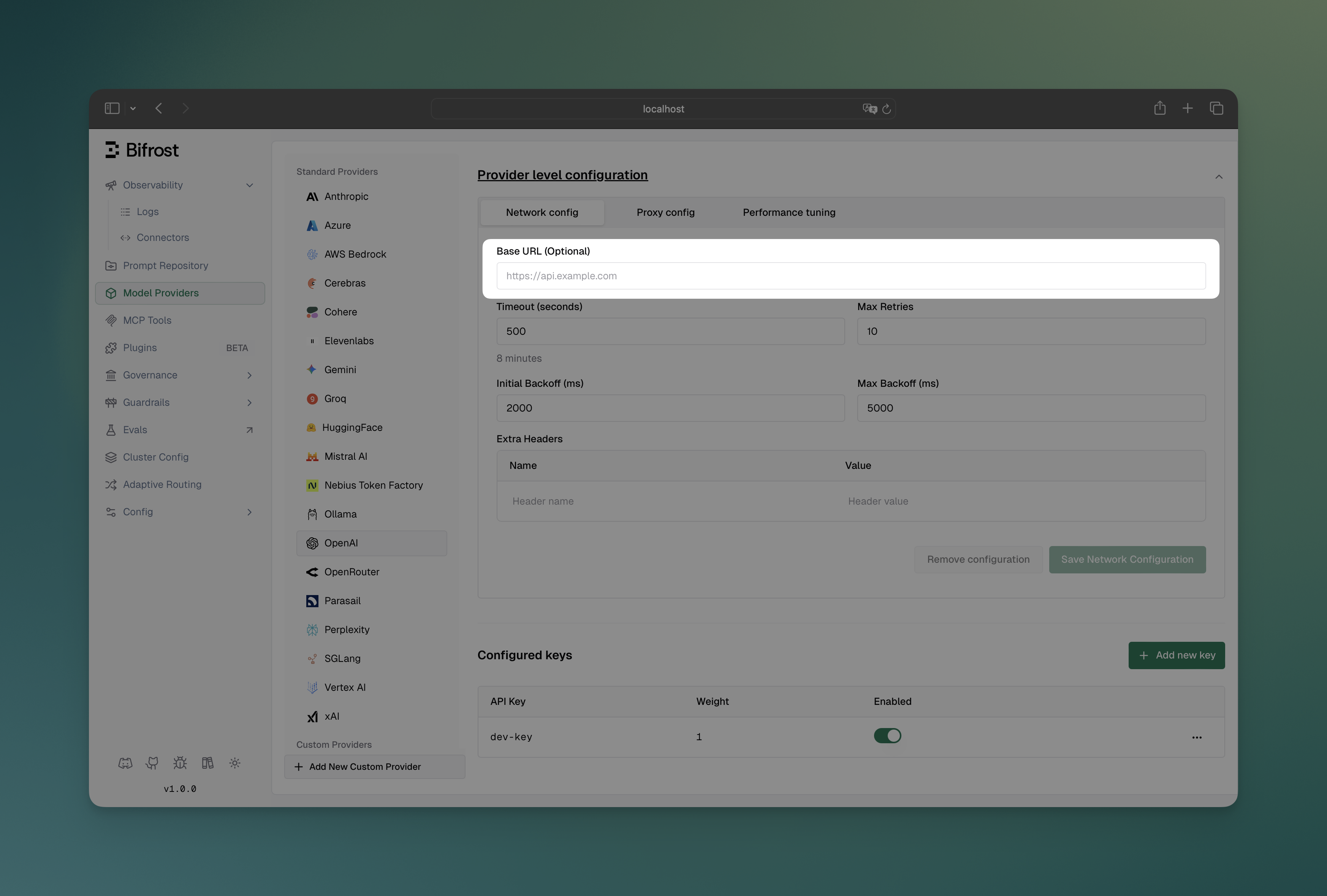
- Navigate to “Model Providers” → “Configurations” → “OpenAI” → “Provider level configuration” → “Network config”
- Set Base URL:
http://localhost:8000/v1 - Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "network_config": { "base_url": "http://localhost:8000/v1" }}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "network_config": { "base_url": "http://localhost:8000/v1" } } }}Managing Retries
Section titled “Managing Retries”Configure retry behavior for handling temporary failures and rate limits. This example sets up exponential backoff with up to 5 retries, starting with 1ms delay and capping at 10 seconds - ideal for handling transient network issues.
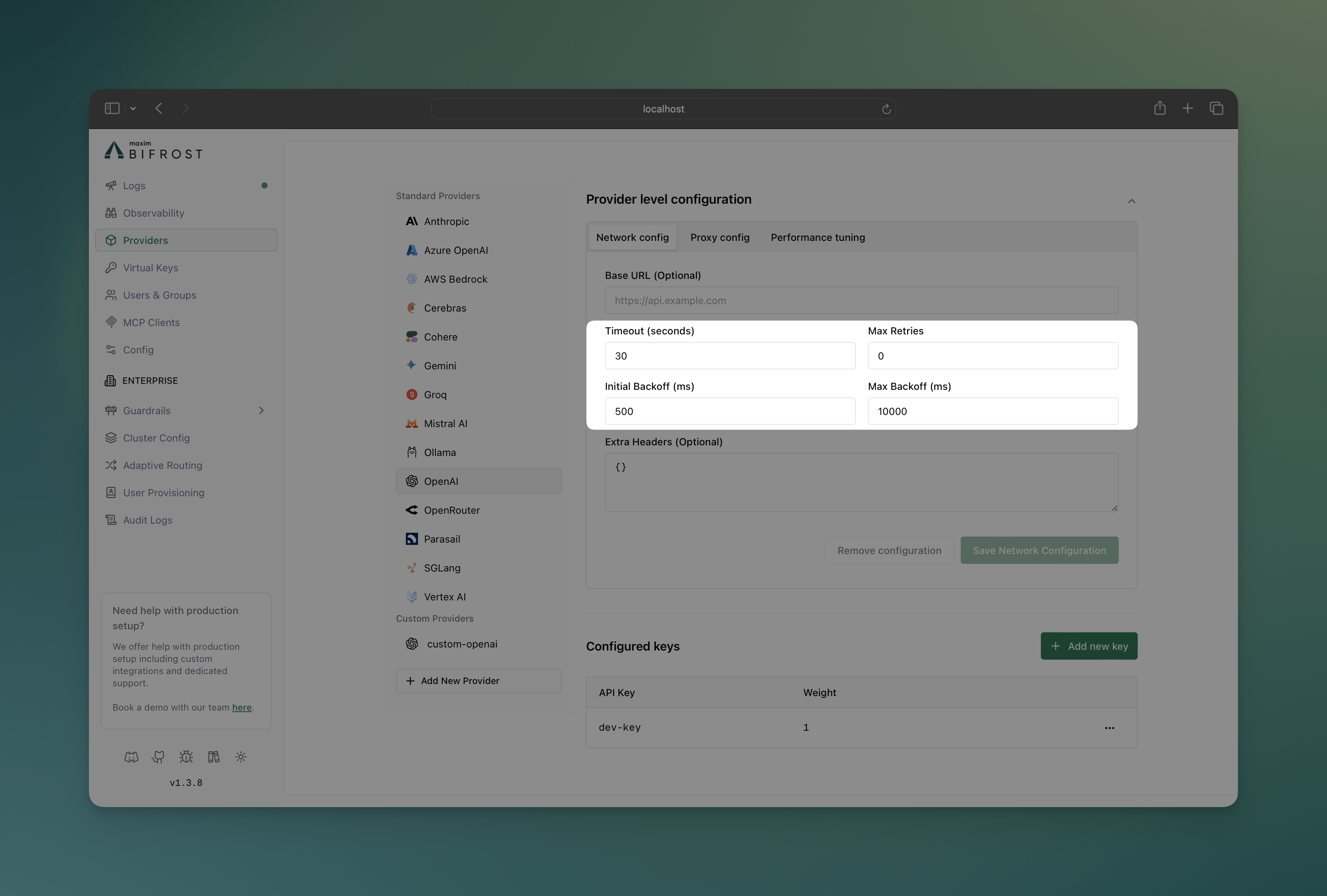
- Navigate to “Model Providers” → “Configurations” → “OpenAI” → “Provider level configuration” → “Network config”
- Set Max Retries:
5 - Set Initial Backoff:
1ms - Set Max Backoff:
10000ms - Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "network_config": { "max_retries": 5, "retry_backoff_initial_ms": 1, "retry_backoff_max_ms": 10000 }}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "network_config": { "max_retries": 5, "retry_backoff_initial_ms": 1, "retry_backoff_max_ms": 10000 } } }}Custom Concurrency and Buffer Size
Section titled “Custom Concurrency and Buffer Size”Fine-tune performance by adjusting worker concurrency and queue sizes per provider (defaults are 1000 workers and 5000 queue size). This example gives OpenAI higher limits (100 workers, 500 queue) for high throughput, while Anthropic gets conservative limits to respect their rate limits.
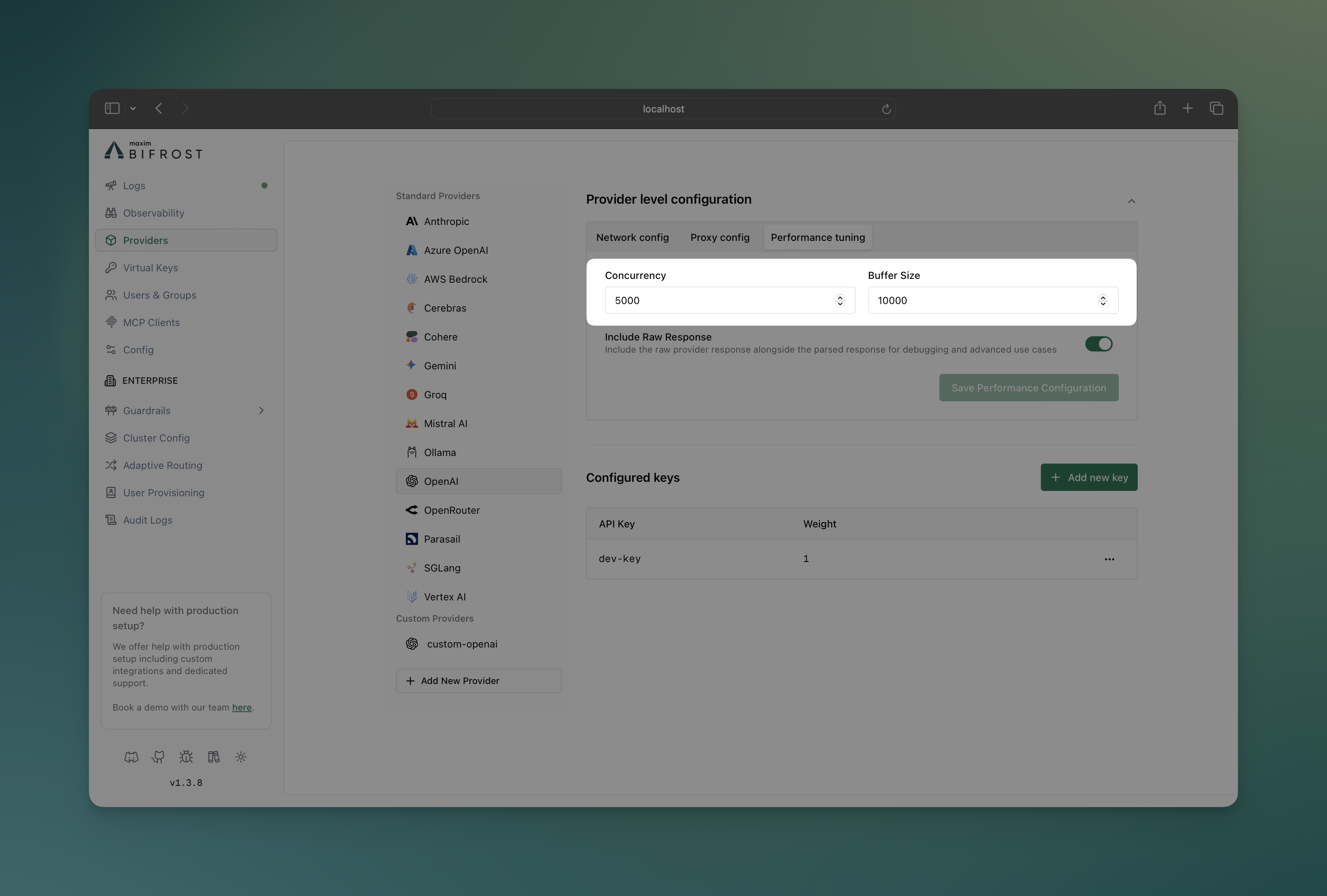
- Navigate to “Model Providers” → “Configurations” → {Provider} → “Provider level configuration” → “Performance tuning”
- Set Concurrency: Worker count (100 for OpenAI, 25 for Anthropic)
- Set Buffer Size: Queue size (500 for OpenAI, 100 for Anthropic)
- Save configuration
# OpenAI with high throughput settingscurl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "concurrency_and_buffer_size": { "concurrency": 100, "buffer_size": 500 }}'
# Anthropic with conservative settingscurl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "anthropic", "keys": [ { "name": "openai-key-1", "value": "env.ANTHROPIC_API_KEY", "models": [], "weight": 1.0 } ], "concurrency_and_buffer_size": { "concurrency": 25, "buffer_size": 100 }}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "concurrency_and_buffer_size": { "concurrency": 100, "buffer_size": 500 } }, "anthropic": { "keys": [ { "name": "anthropic-key-1", "value": "env.ANTHROPIC_API_KEY", "models": [], "weight": 1.0 } ], "concurrency_and_buffer_size": { "concurrency": 25, "buffer_size": 100 } } }}Custom Headers
Section titled “Custom Headers”DeepIntShield supports two ways to add custom headers to provider requests: static headers configured at the provider level, and dynamic headers passed per-request.
Static Headers (Provider Level)
Section titled “Static Headers (Provider Level)”Configure headers that are automatically included in every request to a specific provider. This is useful for provider-specific requirements, API versioning, or organizational metadata.
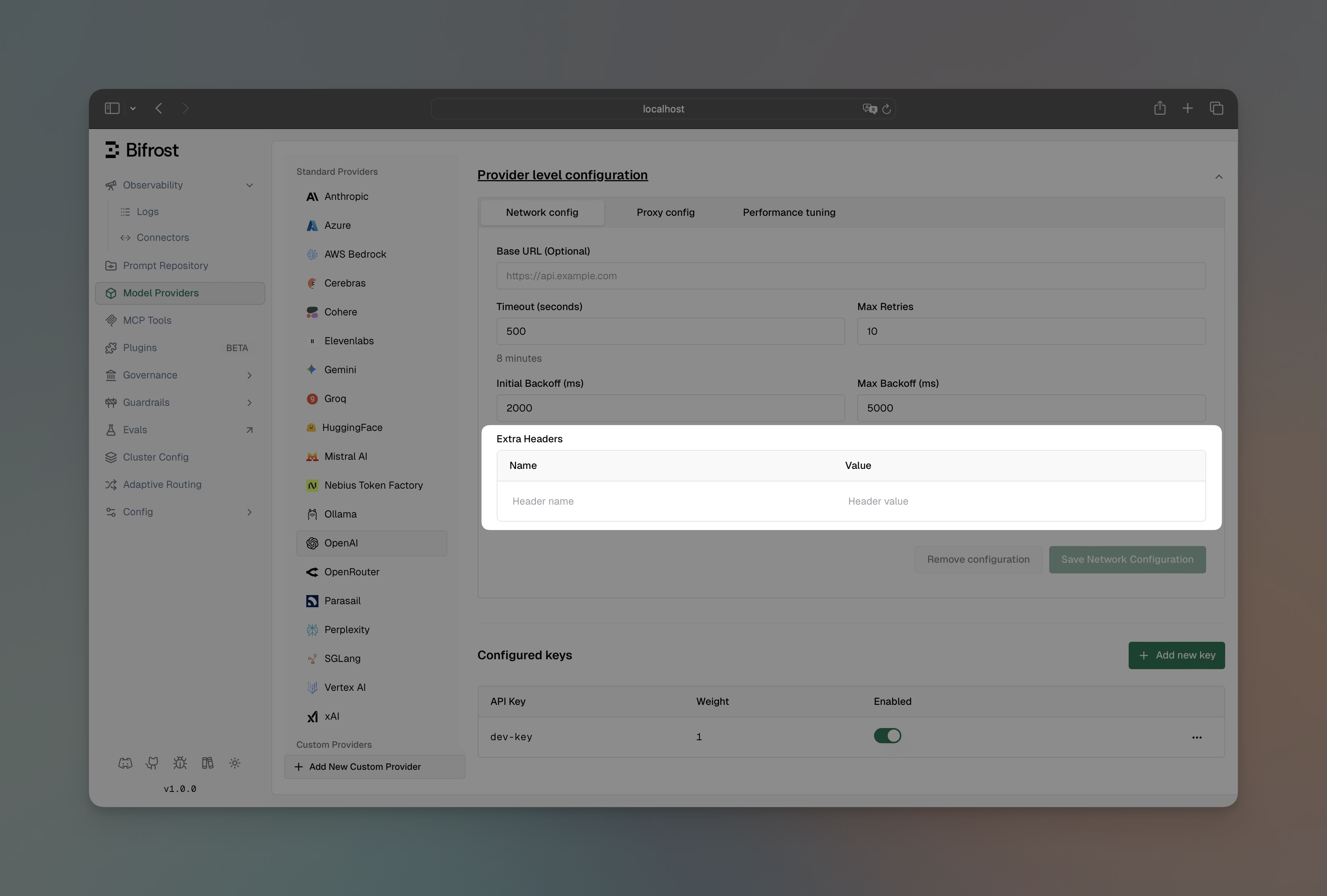
- Navigate to “Model Providers” → “Configurations” → “OpenAI” → “Provider level configuration” → “Network config”
- Add headers in the “Extra Headers” section
- Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "network_config": { "extra_headers": { "x-custom-org": "my-organization", "x-environment": "production" } }}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "network_config": { "extra_headers": { "x-custom-org": "my-organization", "x-environment": "production" } } } }}Dynamic Headers (Per Request)
Section titled “Dynamic Headers (Per Request)”Send custom headers with individual requests using the x-bf-eh-* prefix. Headers are automatically propagated to the provider after stripping the prefix. This is useful for request-specific metadata, user identification, or custom tracking information.
curl --location 'http://localhost:8080/v1/chat/completions' \--header 'Content-Type: application/json' \--header 'x-bf-eh-user-id: user-123' \--header 'x-bf-eh-tracking-id: trace-456' \--data '{ "model": "openai/gpt-4o-mini", "messages": [ {"role": "user", "content": "Hello!"} ]}'The x-bf-eh- prefix is stripped before forwarding, so x-bf-eh-user-id becomes user-id in the request to the provider.
Example use cases:
- User identification:
x-bf-eh-user-id,x-bf-eh-tenant-id - Request tracking:
x-bf-eh-correlation-id,x-bf-eh-trace-id - Custom metadata:
x-bf-eh-department,x-bf-eh-cost-center - A/B testing:
x-bf-eh-experiment-id,x-bf-eh-variant
Security Denylist
Section titled “Security Denylist”DeepIntShield maintains a security denylist of headers that are never forwarded to providers, regardless of configuration:
denylist := map[string]bool{ "proxy-authorization": true, "cookie": true, "host": true, "content-length": true, "connection": true, "transfer-encoding": true,
// prevent auth/key overrides via x-bf-eh-* "x-api-key": true, "x-goog-api-key": true, "x-bf-api-key": true, "x-bf-vk": true,}This denylist is applied to both static and dynamic headers to prevent security vulnerabilities.
Setting Up a Proxy
Section titled “Setting Up a Proxy”Route requests through proxies for compliance, security, or geographic requirements. This example shows both HTTP proxy for OpenAI and authenticated SOCKS5 proxy for Anthropic, useful for corporate environments or regional access.
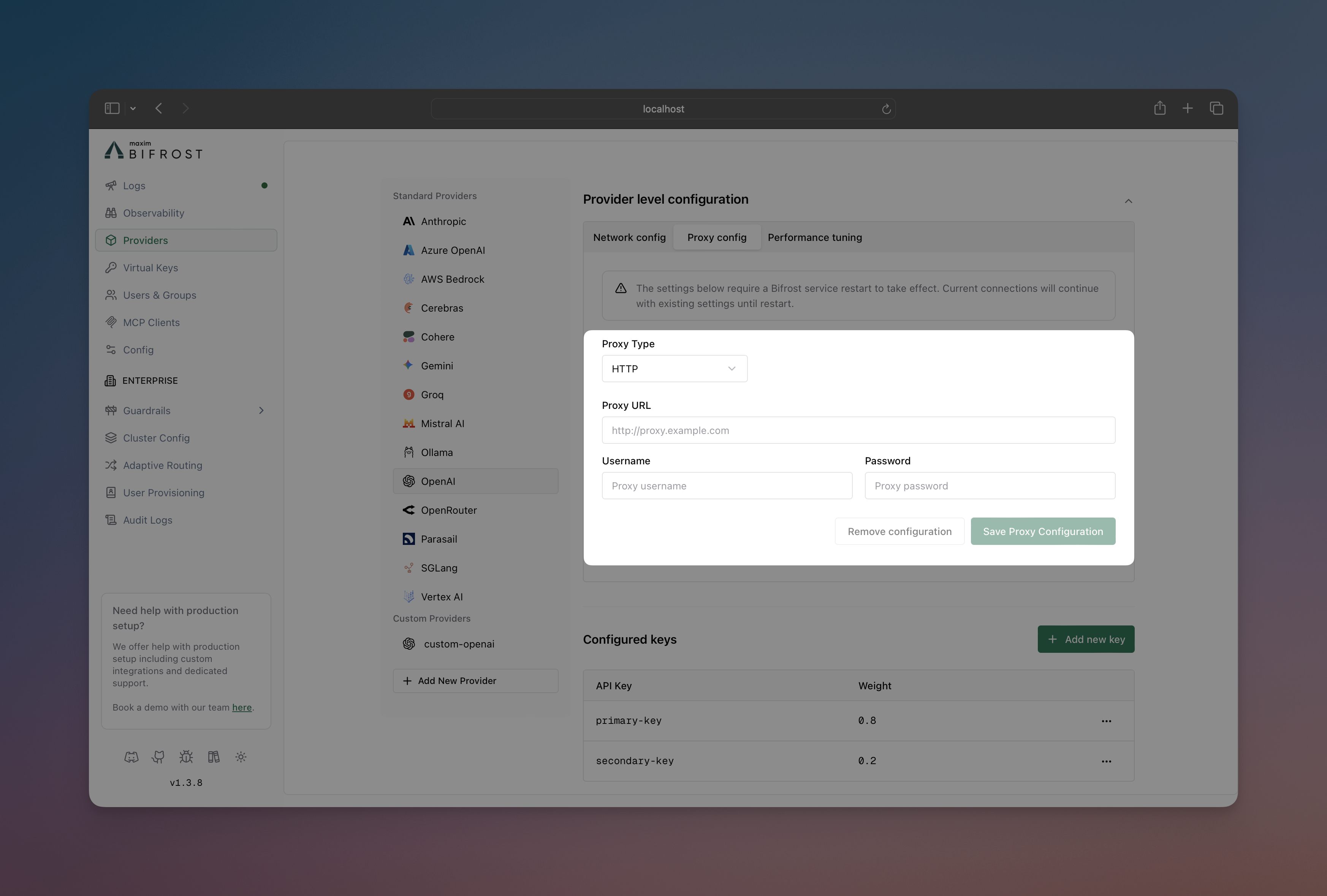
- Navigate to “Model Providers” → “Configurations” → {Provider} → “Provider level configuration” → “Proxy config”
- Select Proxy Type: HTTP or SOCKS5
- Set Proxy URL:
http://localhost:8000 - Add credentials if needed (username/password)
- Save configuration
# HTTP proxy for OpenAIcurl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "proxy_config": { "type": "http", "url": "http://localhost:8000" }}'
# SOCKS5 proxy with authentication for Anthropiccurl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "anthropic", "keys": [ { "name": "anthropic-key-1", "value": "env.ANTHROPIC_API_KEY", "models": [], "weight": 1.0 } ], "proxy_config": { "type": "socks5", "url": "http://localhost:8000", "username": "user", "password": "password" }}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "proxy_config": { "type": "http", "url": "http://localhost:8000" } }, "anthropic": { "keys": [ { "name": "anthropic-key-1", "value": "env.ANTHROPIC_API_KEY", "models": [], "weight": 1.0 } ], "proxy_config": { "type": "socks5", "url": "http://localhost:8000", "username": "user", "password": "password" } } }}Send Back Raw Response
Section titled “Send Back Raw Response”Include the original provider response alongside DeepIntShield’s standardized response format. Useful for debugging and accessing provider-specific metadata.
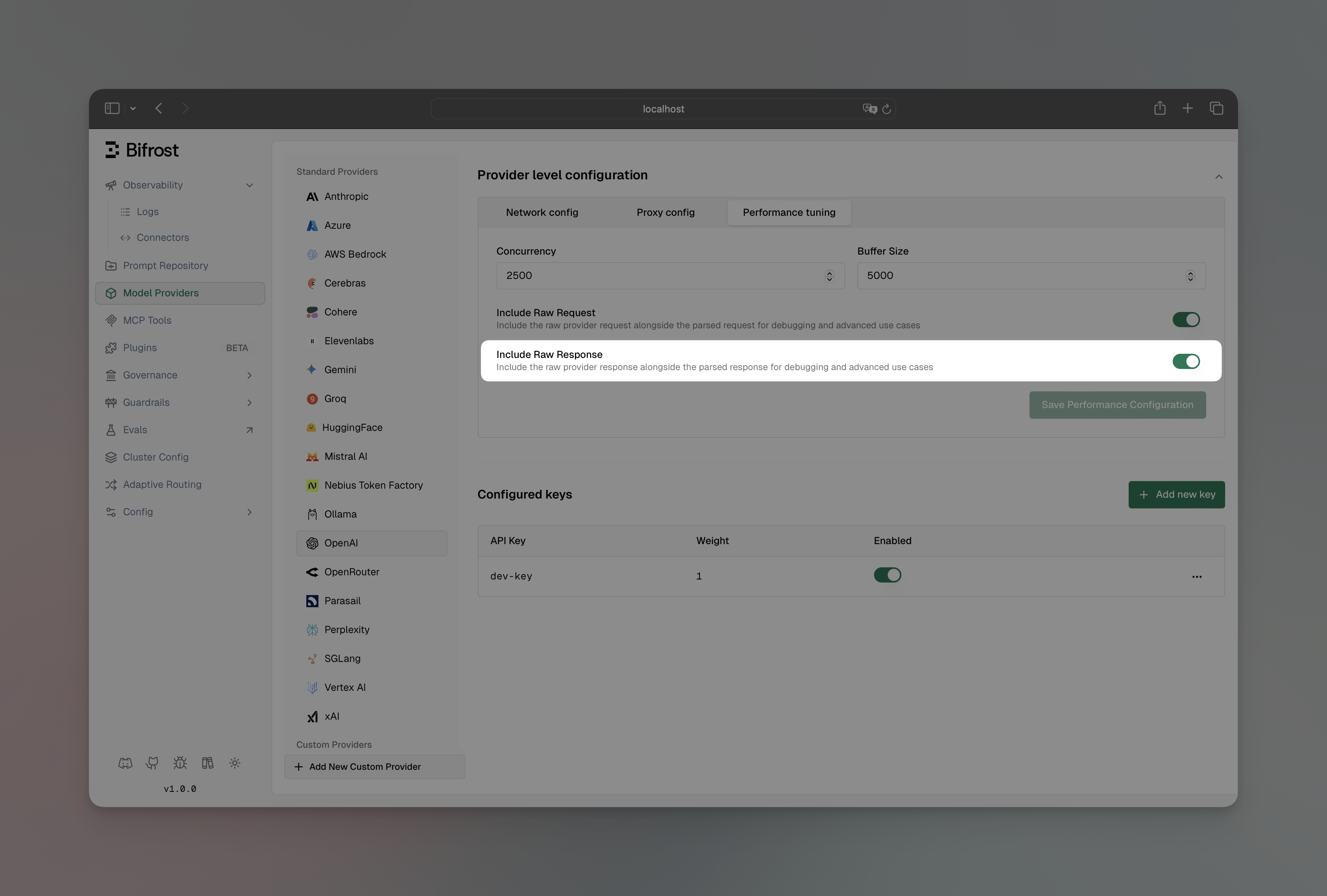
- Navigate to “Model Providers” → “Configurations” → {Provider} → “Provider level configuration” → “Performance tuning”
- Toggle “Include Raw Response” to enabled
- Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "send_back_raw_response": true}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "send_back_raw_response": true } }}When enabled, the raw provider response appears in extra_fields.raw_response:
{ "choices": [...], "usage": {...}, "extra_fields": { "provider": "openai", "raw_response": { // Original OpenAI response here } }}Send Back Raw Request
Section titled “Send Back Raw Request”Include the original request sent to the provider alongside DeepIntShield’s response. Useful for debugging request transformations and verifying what was actually sent to the provider.
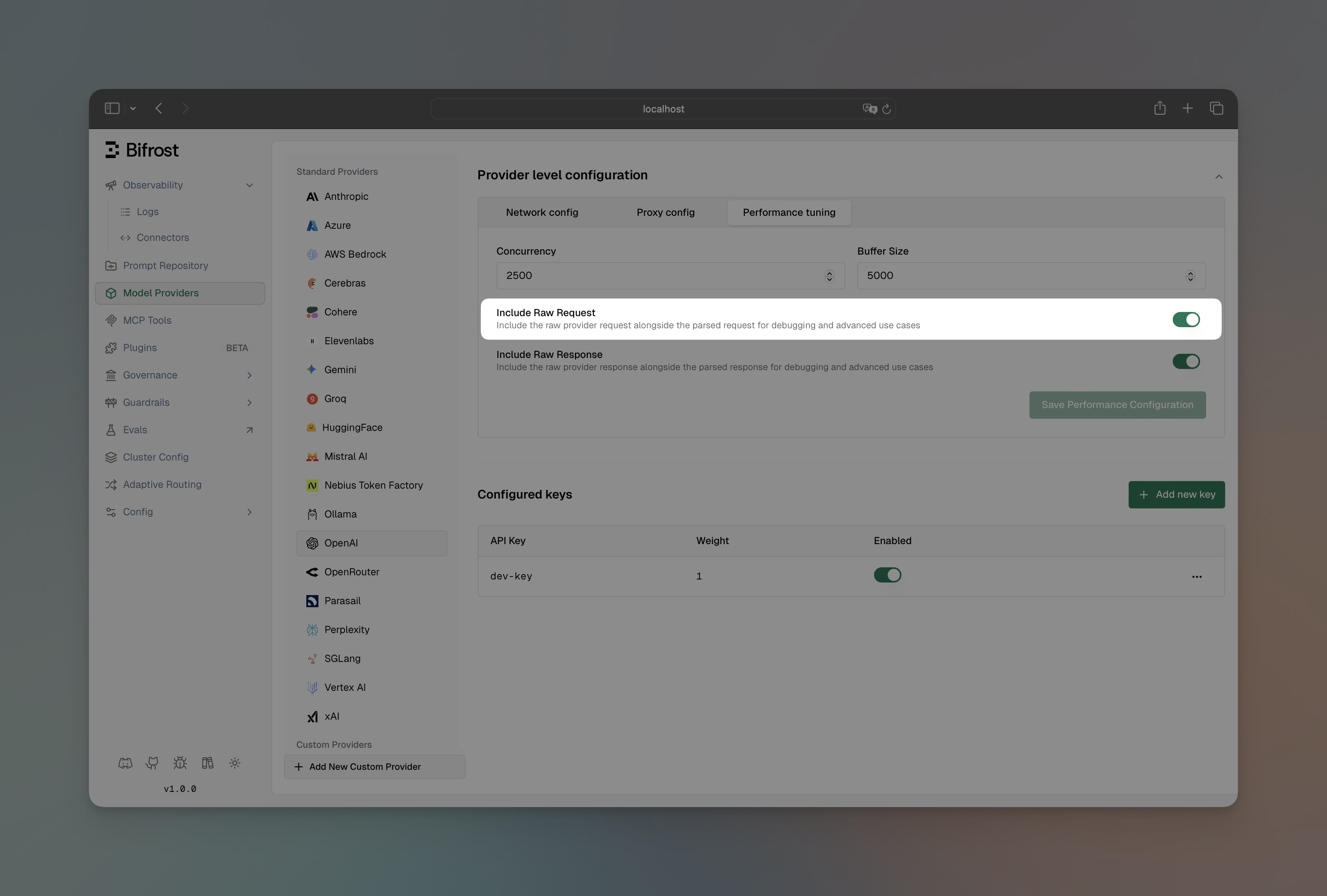
- Navigate to “Model Providers” → “Configurations” → {Provider} → “Provider level configuration” → “Performance tuning”
- Toggle “Include Raw Request” to enabled
- Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "openai", "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "send_back_raw_request": true}'{ "providers": { "openai": { "keys": [ { "name": "openai-key-1", "value": "env.OPENAI_API_KEY", "models": [], "weight": 1.0 } ], "send_back_raw_request": true } }}When enabled, the raw provider request appears in extra_fields.raw_request:
{ "choices": [...], "usage": {...}, "extra_fields": { "provider": "openai", "raw_request": { // Original request sent to OpenAI here } }}Passthrough Extra Parameters
Section titled “Passthrough Extra Parameters”Enable passthrough mode for extra parameters. When enabled, any parameters in the extra_params field (or provider-specific extra parameter fields) will be merged directly into the request sent to the provider, bypassing DeepIntShield’s parameter filtering.
curl --location 'http://localhost:8080/v1/chat/completions' \--header 'Content-Type: application/json' \--header 'x-bf-passthrough-extra-params: true' \--data '{ "model": "openai/gpt-4o-mini", "messages": [ {"role": "user", "content": "Hello!"} ], "extra_params": { "custom_param": "value", "another_param": 123, "nested_param": { "nested_key": "nested_value" } }}'When enabled, the extra parameters are merged into the JSON request body sent to the provider. This allows you to pass provider-specific parameters that DeepIntShield doesn’t natively support.
Provider-Specific Authentication
Section titled “Provider-Specific Authentication”Enterprise cloud providers require additional configuration beyond API keys. Configure Azure, AWS Bedrock, and Google Vertex with platform-specific authentication details.
Azure supports three authentication methods: Managed Identity (DefaultAzureCredential), Entra ID (Service Principal), and Direct (API Key).
Managed Identity / DefaultAzureCredential
Section titled “Managed Identity / DefaultAzureCredential”Leave API key and Entra ID credentials empty. DeepIntShield uses DefaultAzureCredential, which auto-detects managed identity on Azure VMs, App Service, AKS, and similar environments. Provide only endpoint, deployments, and optionally api_version.
Azure Entra ID (Service Principal)
Section titled “Azure Entra ID (Service Principal)”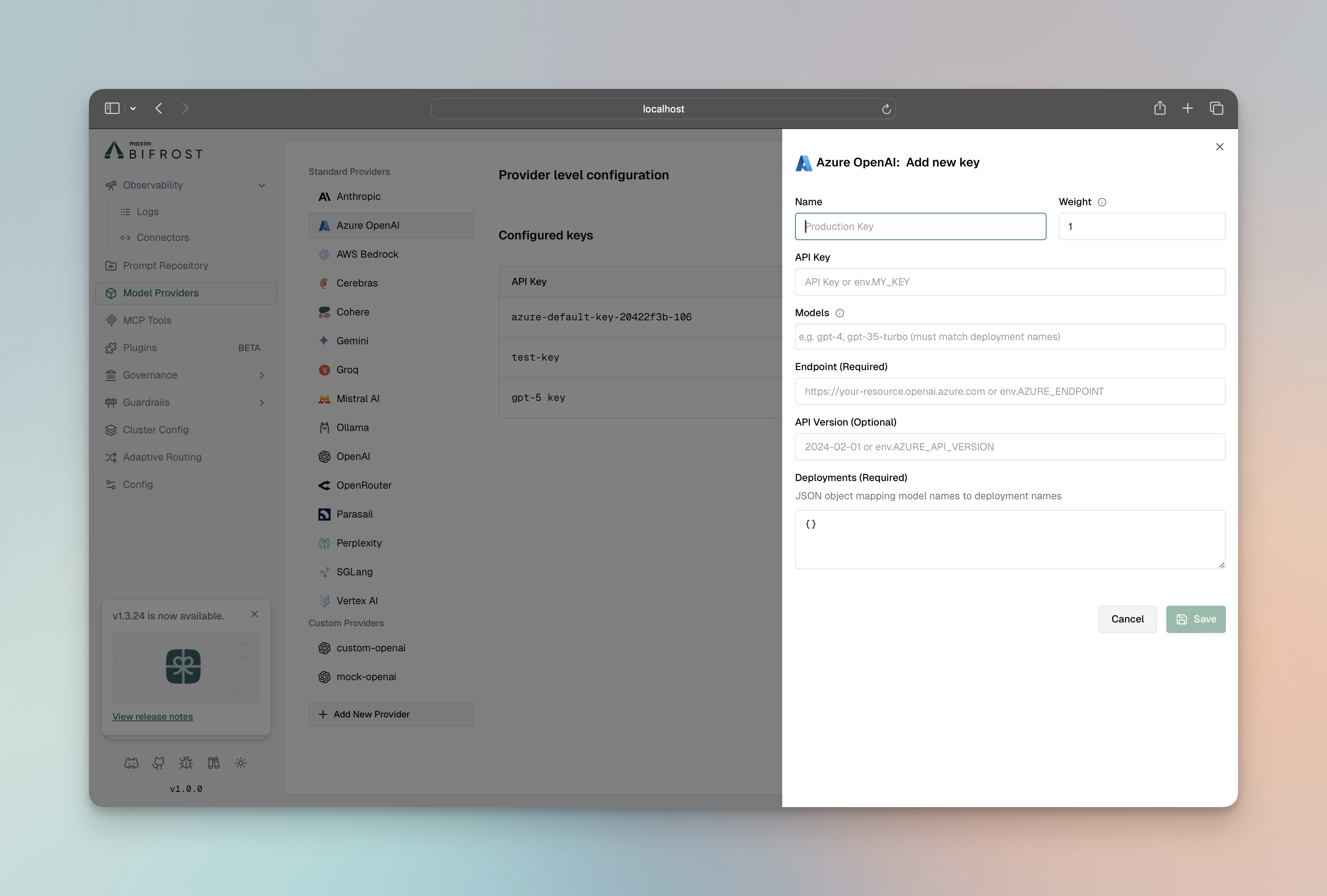
- Navigate to “Model Providers” → “Configurations” → “Azure”
- Leave API Key empty for Service Principal auth
- Set Client ID: Your Azure Entra ID client ID
- Set Client Secret: Your Azure Entra ID client secret
- Set Tenant ID: Your Azure Entra ID tenant ID
- Set Endpoint: Your Azure endpoint URL
- Configure Deployments: Map model names to deployment names
- Set API Version: e.g.,
2024-08-01-preview - Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "azure", "keys": [ { "name": "azure-key-1", "value": "", "models": ["gpt-4o", "gpt-4o-mini"], "weight": 1.0, "azure_key_config": { "endpoint": "env.AZURE_ENDPOINT", "client_id": "env.AZURE_CLIENT_ID", "client_secret": "env.AZURE_CLIENT_SECRET", "tenant_id": "env.AZURE_TENANT_ID", "scopes": ["https://cognitiveservices.azure.com/.default"], "deployments": { "gpt-4o": "gpt-4o-deployment", "gpt-4o-mini": "gpt-4o-mini-deployment" }, "api_version": "2024-08-01-preview" } } ]}'{ "providers": { "azure": { "keys": [ { "name": "azure-key-1", "value": "", "models": ["gpt-4o", "gpt-4o-mini"], "weight": 1.0, "azure_key_config": { "endpoint": "env.AZURE_ENDPOINT", "client_id": "env.AZURE_CLIENT_ID", "client_secret": "env.AZURE_CLIENT_SECRET", "tenant_id": "env.AZURE_TENANT_ID", "scopes": ["https://cognitiveservices.azure.com/.default"], "deployments": { "gpt-4o": "gpt-4o-deployment", "gpt-4o-mini": "gpt-4o-mini-deployment" }, "api_version": "2024-08-01-preview" } } ] } }}Direct Authentication
Section titled “Direct Authentication”For simpler use cases, provide the authentication credential directly in the value field:
- Navigate to “Model Providers” → “Configurations” → “Azure”
- Set API Key: Your Azure API key
- Set Endpoint: Your Azure endpoint URL
- Configure Deployments: Map model names to deployment names
- Set API Version: e.g.,
2024-08-01-preview - Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "azure", "keys": [ { "name": "azure-key-1", "value": "env.AZURE_API_KEY", "models": ["gpt-4o", "gpt-4o-mini"], "weight": 1.0, "azure_key_config": { "endpoint": "env.AZURE_ENDPOINT", "deployments": { "gpt-4o": "gpt-4o-deployment", "gpt-4o-mini": "gpt-4o-mini-deployment" }, "api_version": "2024-08-01-preview" } } ]}'{ "providers": { "azure": { "keys": [ { "name": "azure-key-1", "value": "env.AZURE_API_KEY", "models": ["gpt-4o", "gpt-4o-mini"], "weight": 1.0, "azure_key_config": { "endpoint": "env.AZURE_ENDPOINT", "deployments": { "gpt-4o": "gpt-4o-deployment", "gpt-4o-mini": "gpt-4o-mini-deployment" }, "api_version": "2024-08-01-preview" } } ] } }}AWS Bedrock
Section titled “AWS Bedrock”AWS Bedrock supports both explicit credentials and IAM role authentication:
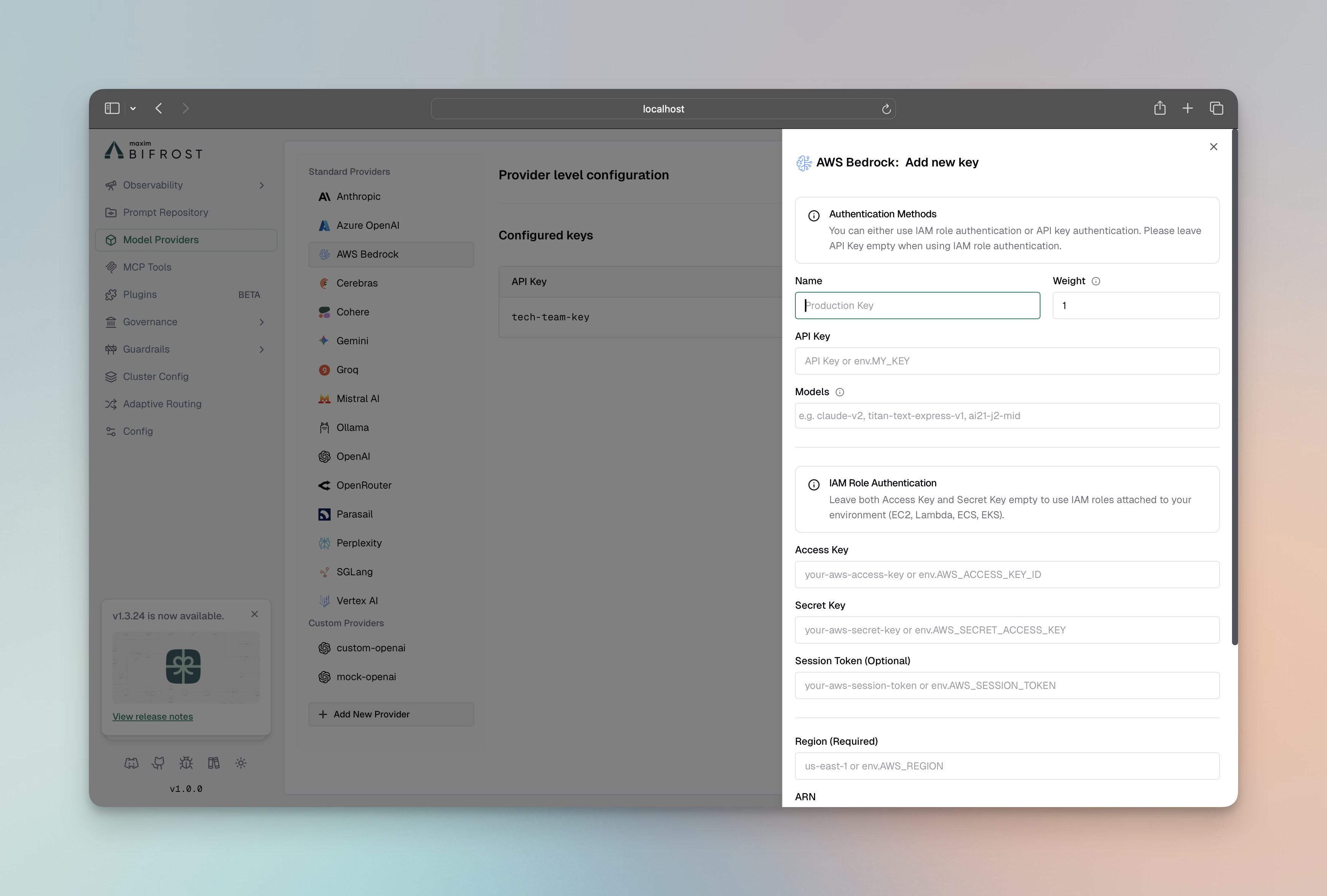
- Navigate to “Model Providers” → “Configurations” → “AWS Bedrock”
- Set API Key: AWS API Key (or leave empty if using IAM role authentication)
- Set Access Key: AWS Access Key ID (or leave empty to use IAM in environment)
- Set Secret Key: AWS Secret Access Key (or leave empty to use IAM in environment)
- Set Region: e.g.,
us-east-1 - Configure Deployments: Map model names to inference profiles
- Set ARN: Required for deployments mapping
- Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "bedrock", "keys": [ { "name": "bedrock-key-1", "models": ["anthropic.claude-3-sonnet-20240229-v1:0", "anthropic.claude-v2:1"], "weight": 1.0, "bedrock_key_config": { "access_key": "env.AWS_ACCESS_KEY_ID", "secret_key": "env.AWS_SECRET_ACCESS_KEY", "session_token": "env.AWS_SESSION_TOKEN", "region": "us-east-1", "deployments": { "claude-3-sonnet": "us.anthropic.claude-3-sonnet-20240229-v1:0" }, "arn": "arn:aws:bedrock:us-east-1:123456789012:inference-profile" } } ]}'{ "providers": { "bedrock": { "keys": [ { "name": "bedrock-key-1", "models": ["anthropic.claude-3-sonnet-20240229-v1:0", "anthropic.claude-v2:1"], "weight": 1.0, "bedrock_key_config": { "access_key": "env.AWS_ACCESS_KEY_ID", "secret_key": "env.AWS_SECRET_ACCESS_KEY", "session_token": "env.AWS_SESSION_TOKEN", "region": "us-east-1", "deployments": { "claude-3-sonnet": "us.anthropic.claude-3-sonnet-20240229-v1:0" }, "arn": "arn:aws:bedrock:us-east-1:123456789012:inference-profile" } } ] } }}Notes:
- If using API Key authentication, set
valuefield to the API key, else leave it empty for IAM role authentication. - In IAM role authentication, if both
access_keyandsecret_keyare empty, DeepIntShield uses IAM role authentication from the environment. arnis required for URL formation -deploymentsmapping is ignored without it.- When using
arn+deployments, DeepIntShield uses model profiles; otherwise forms path with incoming model name directly. - ARN vs deployments: Put the ARN prefix in
arnand the model/inference profile resource ID only indeployments— never the full ARN in deployments. See How to Use ARNs and Application Inference Profiles for details.
Google Vertex
Section titled “Google Vertex”Google Vertex requires project configuration and authentication credentials:
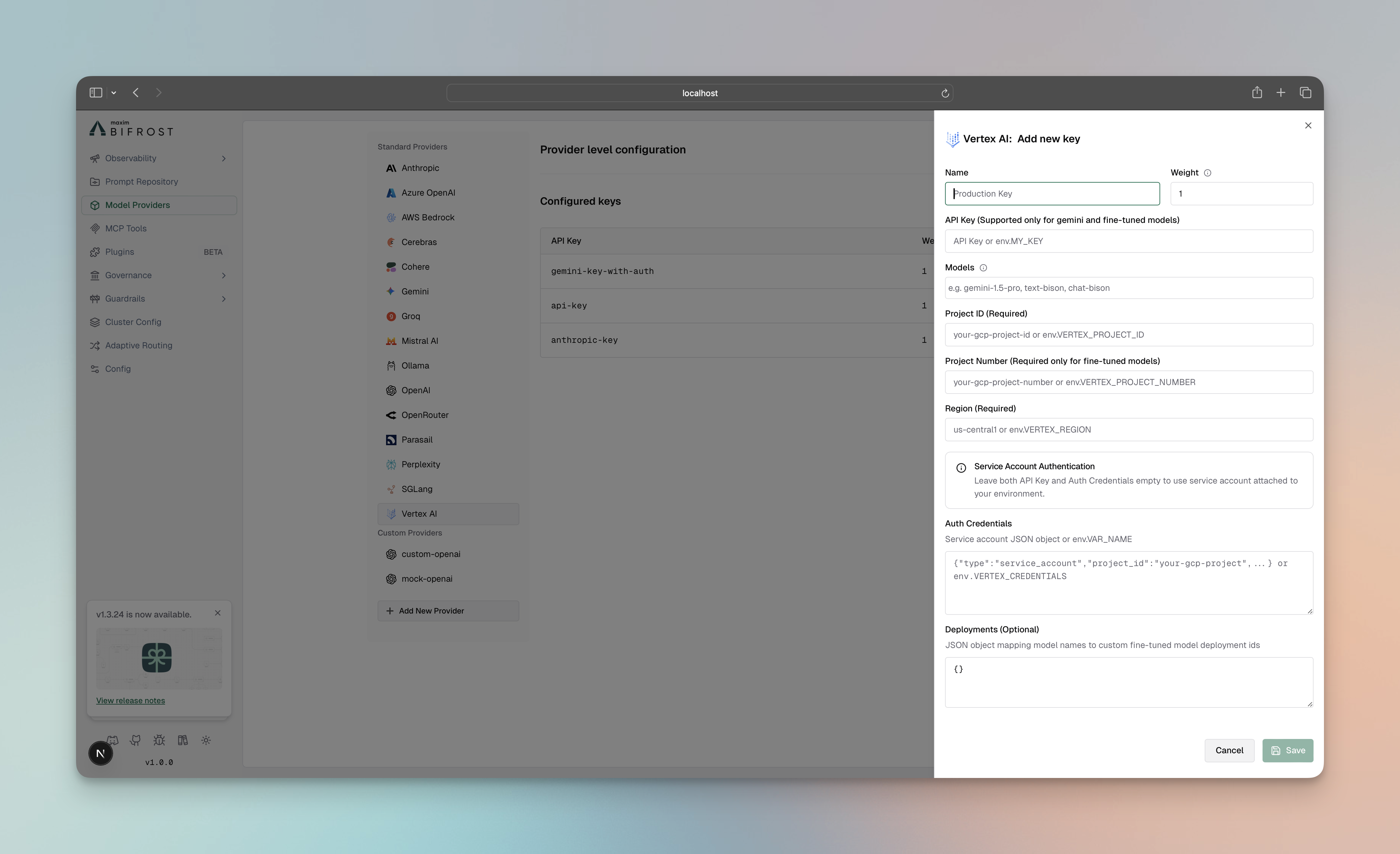
- Navigate to “Model Providers” → “Configurations” → “Google Vertex”
- Set API Key: Your Vertex API key
- Set Project ID: Your Google Cloud project ID
- Set Region: e.g.,
us-central1 - Set Auth Credentials: Service account credentials JSON
- Save configuration
curl --location 'http://localhost:8080/api/providers' \--header 'Content-Type: application/json' \--data '{ "provider": "vertex", "keys": [ { "name": "vertex-key-1", "value": "env.VERTEX_API_KEY", "models": ["gemini-pro", "gemini-pro-vision"], "weight": 1.0, "vertex_key_config": { "project_id": "env.VERTEX_PROJECT_ID", "region": "us-central1", "auth_credentials": "env.VERTEX_CREDENTIALS", "deployments": { "fine-tuned-gemini-2.5-pro": "123456789" } } } ]}'{ "providers": { "vertex": { "keys": [ { "name": "vertex-key-1", "value": "env.VERTEX_API_KEY", "models": ["gemini-pro", "gemini-pro-vision"], "weight": 1.0, "vertex_key_config": { "project_id": "env.VERTEX_PROJECT_ID", "region": "us-central1", "auth_credentials": "env.VERTEX_CREDENTIALS", "deployments": { "fine-tuned-gemini-2.5-pro": "123456789" } } } ] } }}Notes:
- You can leave both API Key and Auth Credentials empty to use service account authentication from the environment.
- You must set Project Number in Key config if using fine-tuned models.
- API Key Authentication is only supported for Gemini and fine-tuned models.
- You can use custom fine-tuned models by passing
vertex/<your-fine-tuned-model-id>orvertex/<model-deployment-alias>if you have set the deployments in the key config.
Next Steps
Section titled “Next Steps”Now that you understand provider configuration, explore these related topics:
Essential Topics
Section titled “Essential Topics”- Streaming Responses - Real-time response generation
- Tool Calling - Enable AI to use external functions
- Multimodal AI - Process images, audio, and text
- Integrations - Drop-in compatibility with existing SDKs
Advanced Topics
Section titled “Advanced Topics”- Core Features - Advanced DeepIntShield capabilities
- Architecture - How DeepIntShield works internally
- Deployment - Production setup and scaling